Large Language Models (LLM): Complete Guide to Architecture, Training & Applications
Master Large Language Models (LLMs) from transformer architecture to real-world applications. Comprehensive guide covering GPT, training techniques, and deployment strategies.
Large Language Models (LLM): Complete Guide to Architecture, Training & Applications (2026)
Large Language Models (LLMs) have fundamentally transformed how we interact with AI, from simple chatbots to sophisticated code generators and creative writing assistants. But understanding what makes these models tick goes beyond just using ChatGPT or Claude.
In 2026, LLMs have become more powerful, efficient, and accessible than ever. Yet most developers and AI practitioners struggle with understanding the underlying architecture, training methodologies, and real-world deployment strategies that make these models work.
This comprehensive guide takes you from the foundational transformer architecture to advanced training techniques, covering everything you need to understand and work with Large Language Models effectively. Whether you’re an AI researcher, software engineer, or technical leader, you’ll gain deep insights into how LLMs work and how to leverage them for real-world applications.
What You'll Learn
This guide covers everything from transformer fundamentals to production deployment:
- Deep dive into transformer architecture and attention mechanisms
- Training methodologies including pre-training, fine-tuning, and RLHF
- Scaling laws and model optimization techniques
- Real-world applications and deployment strategies
- Best practices for prompt engineering and model selection
What Are Large Language Models? (Definition + Evolution)
Large Language Models (LLMs) are neural networks trained on massive amounts of text data to understand and generate human-like language. Unlike traditional rule-based systems or smaller models, LLMs leverage billions (sometimes trillions) of parameters to capture complex patterns in language, context, and reasoning.
Key characteristics that define LLMs:
- Scale: Typically billions of parameters (GPT-3: 175B, GPT-4: estimated 1.7T)
- Pre-training: Trained on diverse internet-scale text data
- Transfer learning: Can be fine-tuned for specific tasks
- Few-shot learning: Can learn new tasks from just a few examples
- Emergent abilities: Capabilities that appear only at scale (reasoning, arithmetic, etc.)
The evolution of LLMs can be traced through several key milestones:
| Year | Model | Parameters | Key Innovation |
|---|---|---|---|
| 2017 | Transformer | - | Self-attention mechanism |
| 2018 | BERT | 340M | Bidirectional pre-training |
| 2018 | GPT-1 | 117M | Generative pre-training |
| 2019 | GPT-2 | 1.5B | Scale + zero-shot learning |
| 2020 | GPT-3 | 175B | Few-shot in-context learning |
| 2022 | ChatGPT | 175B | RLHF, conversational ability |
| 2023 | GPT-4 | 1.7T (est.) | Multimodal, advanced reasoning |
| 2026 | Claude 3 | Unknown | Long context (200K tokens) |
Modern Context
In 2026, we’re seeing a shift from pure scale to efficiency. Models like Mistral 7B and Llama 2 achieve impressive performance with fewer parameters through better training data and techniques.
Why LLMs Matter (Impact + Use Cases)
LLMs represent one of the most significant breakthroughs in AI because they’ve made natural language understanding and generation accessible at scale. Here’s why they matter:
- Democratize AI access: Anyone can now interact with sophisticated AI through natural language
- Accelerate development: Generate code, documentation, and tests in seconds
- Enhance creativity: Assist with writing, brainstorming, and content creation
- Improve accessibility: Translate languages, simplify complex text, summarize information
- Enable automation: Handle customer support, data analysis, and research tasks
- Drive innovation: Power new applications from legal tech to healthcare diagnostics
Real-world business impact:
- Productivity gains of 20-40% for knowledge workers using LLM assistants
- Reduction in customer support costs through intelligent chatbots
- Faster time-to-market for software products with AI-assisted development
- Enhanced research capabilities across scientific domains
Transformer Architecture: The Foundation of LLMs
At the heart of every modern LLM is the Transformer architecture, introduced in the seminal 2017 paper “Attention Is All You Need” by Vaswani et al. Understanding transformers is crucial to understanding LLMs.
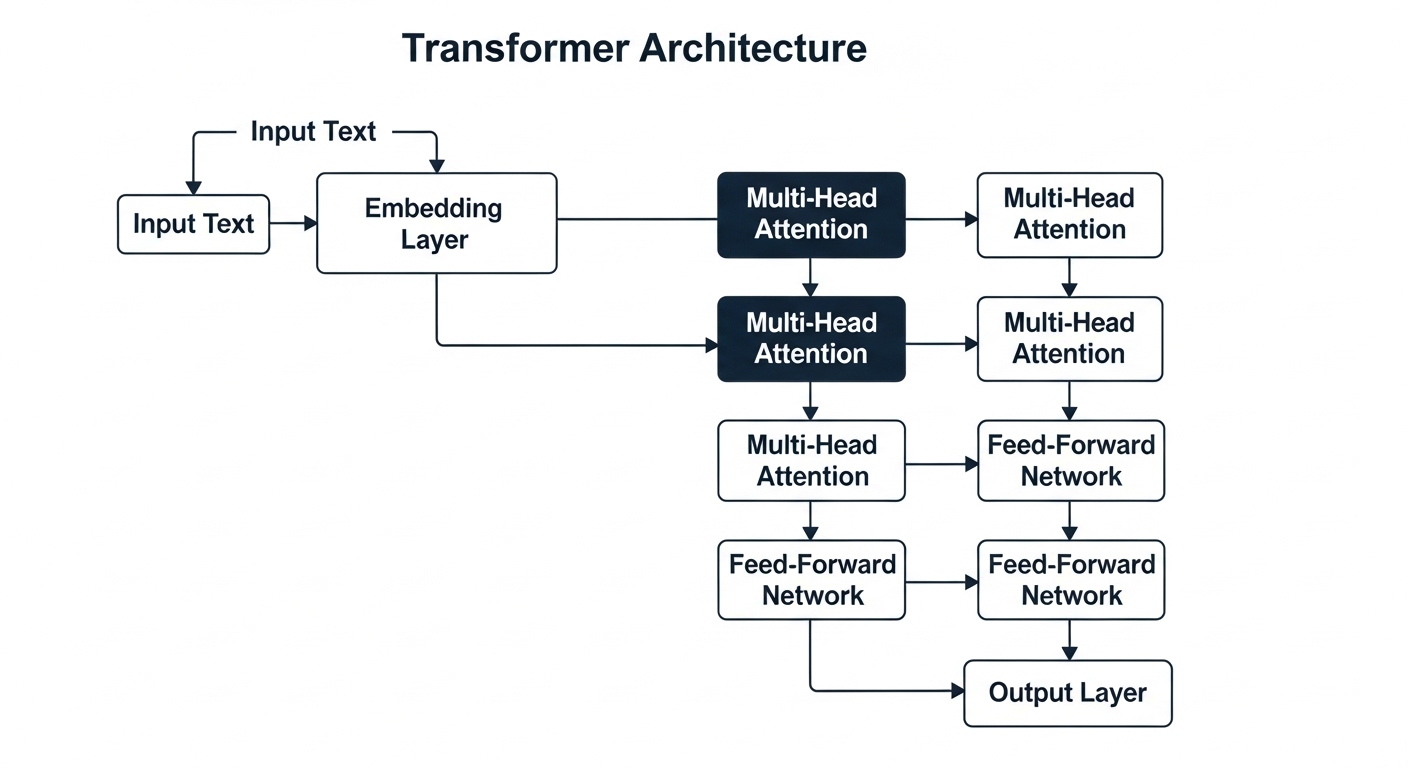
The Core Innovation: Self-Attention
The transformer’s key innovation is the self-attention mechanism, which allows the model to weigh the importance of different words in a sequence when processing each word. This mechanism computes attention scores between all pairs of words in a sequence, allowing the model to focus on relevant context when processing each token.
Multi-Head Attention
Instead of performing attention once, transformers use multiple attention heads in parallel, allowing the model to focus on different aspects of the input simultaneously. Each head learns to attend to different types of relationships in the data.
Complete Transformer Block
A complete transformer block combines multi-head attention with feed-forward networks and layer normalization. The block uses residual connections and layer normalization to enable stable training of deep networks.
Key Architectural Components
Essential Transformer Components
Every transformer-based LLM consists of:
- Tokenization: Converting text to numerical tokens
- Embedding layer: Mapping tokens to dense vectors
- Positional encoding: Adding position information
- Transformer blocks: Stacked self-attention + FFN layers
- Output layer: Predicting next token probabilities
Training Large Language Models: From Pre-training to Fine-tuning
Training LLMs is a multi-stage process that requires massive computational resources and careful methodology. Let’s break down each stage:
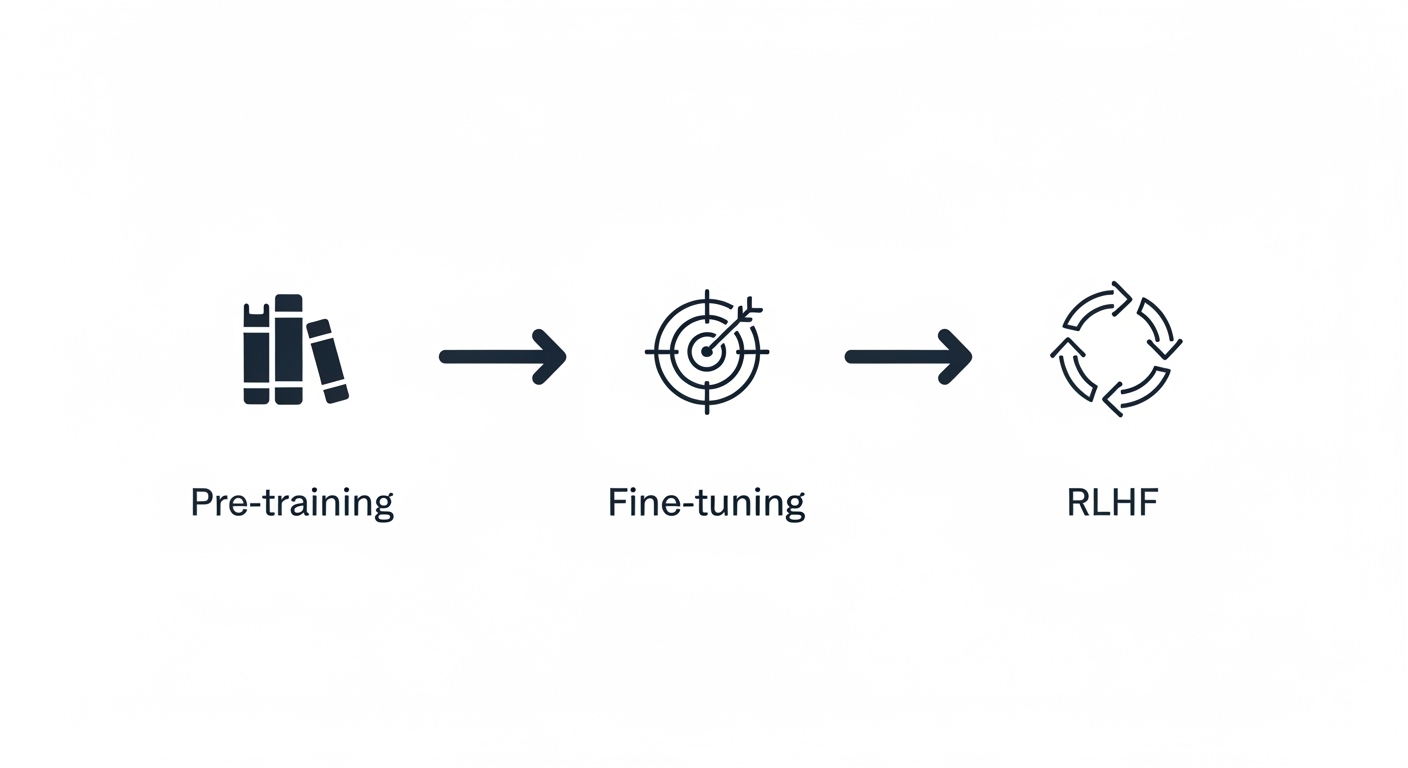
Stage 1: Pre-training (Foundation)
Pre-training is where the model learns general language understanding by predicting the next word in billions of text sequences.
Key characteristics:
- Objective: Next-token prediction (autoregressive modeling)
- Data: Massive diverse text corpora (books, web pages, code, etc.)
- Scale: Weeks to months on thousands of GPUs/TPUs
- Cost: $2M - $100M+ depending on model size
The pre-training objective uses cross-entropy loss to train the model to predict the next token in a sequence. The model processes input tokens and learns to predict what comes next, gradually building up an understanding of language patterns, grammar, and knowledge.
Stage 2: Fine-tuning (Specialization)
After pre-training, models are fine-tuned on specific tasks or domains to improve performance for particular use cases.
Common fine-tuning approaches:
- Supervised fine-tuning (SFT): Train on labeled examples for specific tasks
- Instruction tuning: Train to follow user instructions more effectively
- Domain adaptation: Adapt to specialized domains (medical, legal, code)
- Parameter-efficient fine-tuning: LoRA, adapters, prompt tuning
LoRA (Low-Rank Adaptation) is a popular technique for efficient fine-tuning. Instead of updating all model parameters, LoRA adds small trainable matrices that capture task-specific adaptations. This approach trains only about 0.1% of parameters, making it much faster and cheaper than full fine-tuning while maintaining comparable performance. You can also swap different LoRA adapters for different tasks without changing the base model.
Stage 3: Reinforcement Learning from Human Feedback (RLHF)
RLHF is the secret sauce that makes chatbots like ChatGPT so effective. It aligns model outputs with human preferences.
RLHF process:
- Collect comparison data: Humans rank multiple model outputs
- Train reward model: Learn to predict human preferences
- Optimize with RL: Use PPO to maximize reward
RLHF Challenges
- Expensive: Requires extensive human annotation
- Reward hacking: Models may exploit reward model weaknesses
- Distribution shift: May harm performance on some tasks
- Alignment tax: Trade-off between helpfulness and harmlessness
Scaling Laws: Understanding Model Performance
One of the most important discoveries in LLM research is that model performance follows predictable scaling laws based on three factors:
- Model size (number of parameters)
- Dataset size (number of training tokens)
- Compute budget (FLOPs used for training)
The Chinchilla Scaling Law
Research from DeepMind (Hoffmann et al., 2022) revealed that many large models are over-parameterized and under-trained. The optimal approach:
For given compute budget C:
- Model parameters N ≈ C^0.5
- Training tokens D ≈ C^0.5
Key insight: Double the parameters → double the training data
This means a 70B model trained on 1.4T tokens (Llama 2) can outperform a 175B model trained on 300B tokens (GPT-3).
Practical Takeaway
When training or choosing LLMs, data quality and quantity matter as much as model size. A smaller, well-trained model often beats a larger, undertrained one.
Emergent Abilities at Scale
Certain capabilities only appear when models reach sufficient scale:
- Chain-of-thought reasoning: Step-by-step problem solving
- Arithmetic: Multi-digit calculations
- Code execution: Understanding and generating working code
- Multi-step planning: Breaking down complex tasks
Real-World Applications of LLMs
LLMs have moved from research labs to production systems across industries. Here are the most impactful applications:

1. Code Generation & Software Development
LLMs like GitHub Copilot, GPT-4, and Claude are transforming how developers write code.
Use cases:
- Auto-completing code as you type
- Generating entire functions from natural language descriptions
- Writing tests and documentation
- Debugging and explaining code
- Translating between programming languages
LLMs can be integrated via APIs to generate code on demand. You provide a natural language description of what you want, and the model generates the corresponding code. For code generation, using a lower temperature setting helps produce more deterministic and reliable results.
2. Customer Support & Chatbots
Intelligent chatbots powered by LLMs can handle complex customer queries with human-like understanding.
- 24/7 availability with consistent quality
- Handle multiple languages without separate models
- Escalate to humans when necessary
- Learn from conversation history
- Reduce support costs by 30-70%
3. Content Creation & Marketing
LLMs accelerate content production while maintaining quality:
- Blog posts and articles
- Social media captions
- Email campaigns
- Product descriptions
- Ad copy generation
4. Research & Knowledge Work
LLMs help researchers and analysts work more efficiently:
- Literature review and summarization
- Data analysis and interpretation
- Report generation
- Hypothesis generation
- Citation and reference management
5. Education & Tutoring
Personalized learning at scale:
- Adaptive tutoring systems
- Homework help and explanation
- Practice problem generation
- Language learning
- Accessibility for diverse learners
Prompt Engineering: Getting the Best Results from LLMs
Prompt engineering is the art and science of crafting inputs that elicit desired outputs from LLMs. It’s become a critical skill for anyone working with these models.
Key Principles of Effective Prompting
- Be specific: Vague prompts get vague results
- Provide context: Background information improves accuracy
- Use examples: Few-shot learning works remarkably well
- Specify format: Tell the model how to structure outputs
- Iterate: Refine prompts based on results
Common Prompting Techniques
1. Zero-shot prompting: Asking the model to perform a task without any examples, relying purely on its pre-trained knowledge.
2. Few-shot prompting: Providing a few examples of the task before asking the model to perform it. This dramatically improves accuracy for many tasks.
3. Chain-of-thought prompting: Asking the model to explain its reasoning step-by-step before providing an answer. This improves performance on complex reasoning tasks.
4. Role-based prompting: Assigning the model a specific role or expertise to guide its responses and tone.
Advanced Prompt Patterns
For production applications, create reusable prompt templates with consistent system instructions and structured user prompts. System prompts define the AI’s behavior and personality, while user prompts can be templated with placeholders for dynamic content. This approach ensures consistency across your application and makes it easier to test and iterate on prompt effectiveness.
Prompt Engineering Best Practices
- Start simple, then add complexity
- Test prompts on diverse examples
- Version control your prompts
- Measure prompt effectiveness quantitatively
- Build prompt libraries for common tasks
Deploying LLMs in Production
Moving LLMs from experimentation to production requires careful consideration of performance, cost, and reliability.
Deployment Options
| Approach | Pros | Cons | Best For |
|---|---|---|---|
| API Services (OpenAI, Anthropic) | Easy setup, no infrastructure | Ongoing costs, data privacy | Fast MVP, variable load |
| Managed Platforms (Azure OpenAI, AWS Bedrock) | Enterprise features, compliance | Vendor lock-in | Enterprise apps |
| Self-hosted (Llama 2, Mistral) | Full control, data stays local | Infrastructure complexity | High volume, sensitive data |
| Fine-tuned Models | Optimized for specific tasks | Training costs, maintenance | Domain-specific apps |
Performance Optimization
1. Model quantization: Reduce model size and inference cost without major quality loss. Quantization converts model weights from 32-bit or 16-bit floating point to 8-bit or 4-bit integers. An 8-bit quantized model uses about 50% less memory, while 4-bit quantization reduces memory by approximately 75%, with minimal impact on output quality.
2. Caching: Cache common responses to reduce costs and latency. Implement a caching layer using Redis or similar to store responses for identical or similar prompts. Generate cache keys based on the prompt, model, and parameters. Set appropriate TTL (time-to-live) values based on how often your content changes.
3. Batching: Process multiple requests together for better throughput. Group similar requests and process them in batches to reduce overhead and improve efficiency.
4. Streaming: Stream responses token-by-token for better user experience. Instead of waiting for the complete response, stream tokens as they’re generated, providing immediate feedback to users and improving perceived performance.
Cost Management
LLM inference can be expensive. Key strategies:
- Model selection: Use smaller models where appropriate (GPT-3.5 vs GPT-4)
- Prompt optimization: Shorter prompts = lower costs
- Caching: Avoid redundant API calls
- Batch processing: Process multiple items together
- Rate limiting: Prevent runaway costs from abuse
- Monitoring: Track costs per user, per feature
Challenges & Limitations of LLMs
Despite their impressive capabilities, LLMs have significant limitations that practitioners must understand:
1. Hallucinations
LLMs can confidently generate false information that sounds plausible.
Mitigation Strategies
- Use retrieval-augmented generation (RAG) for factual queries
- Implement fact-checking pipelines
- Show confidence scores when available
- Encourage models to cite sources
- Add human review for critical applications
2. Bias & Fairness
LLMs reflect biases present in training data, which can lead to unfair or harmful outputs.
Common biases:
- Gender bias in professional contexts
- Racial and ethnic stereotypes
- Cultural assumptions
- Socioeconomic bias
3. Context Length Limitations
Most LLMs have limited context windows (4K-200K tokens), restricting their ability to process long documents.
4. Lack of True Understanding
LLMs are pattern matching systems, not reasoning engines. They don’t truly “understand” concepts.
5. Training Data Cutoff
Models only know information from their training data, which has a cutoff date.
6. Computational Cost
Training and running large models requires significant resources and energy.
The Future of Large Language Models
The field of LLMs is evolving rapidly. Here are key trends shaping the future:
1. Multimodal Models
Modern LLMs are becoming multimodal, processing text, images, audio, and video:
- GPT-4 Vision: Image understanding and generation
- Gemini: Native multimodal architecture
- DALL-E, Stable Diffusion: Text-to-image generation
2. Longer Context Windows
New architectures are pushing context limits:
- Claude 3: 200K tokens
- GPT-4 Turbo: 128K tokens
- Research on infinite context methods
3. Mixture of Experts (MoE)
Only activate relevant parts of the model for each task, improving efficiency:
- Mixtral 8x7B: 47B parameters, only uses 13B per token
- Better performance per compute dollar
4. Small Language Models (SLMs)
Focus on efficiency and specialization:
- Phi-2 (2.7B): Matches much larger models on reasoning
- On-device models: Run on phones and edge devices
- Domain-specific models: Optimized for particular industries
5. AI Agents
LLMs as reasoning engines for autonomous agents:
- Tool use and function calling
- Multi-step planning and execution
- Self-correction and learning from feedback
Frequently Asked Questions (FAQs)
What is the difference between GPT-3 and GPT-4?
GPT-4 is OpenAI’s successor to GPT-3 with several key improvements: estimated 1.7 trillion parameters vs 175 billion, multimodal capabilities (can process images), significantly better reasoning and problem-solving, longer context window (128K tokens vs 4K), more reliable and less prone to hallucinations, and better performance on academic and professional benchmarks.
How much does it cost to train a large language model?
Training costs vary dramatically based on model size: Small models (1-7B parameters): $100K - $500K, Medium models (13-70B parameters): $1M - $10M, Large models (175B+ parameters): $10M - $100M+. GPT-3 reportedly cost $4-12M to train, while GPT-4 estimates range from $63-78M. Costs include compute (GPU/TPU clusters), data acquisition and processing, and engineering time.
Can I run an LLM on my own computer?
Yes, but it depends on the model size and your hardware. Options include: Small models (1-7B): Run on consumer GPUs (RTX 3090, 4090) or even CPU with quantization, Medium models (13-30B): Require high-end GPUs (A100, H100) or multiple consumer GPUs, and Large models (70B+): Need multiple enterprise GPUs or cloud infrastructure. Tools like Ollama, LM Studio, and llama.cpp make local deployment easier with quantization.
What is the best LLM for coding?
As of 2026, the top code-focused LLMs are: GPT-4 (OpenAI): Best overall, excellent at complex algorithms and debugging, Claude 3 Opus (Anthropic): Strong code generation, good at following instructions, GitHub Copilot: Best for IDE integration and autocomplete, Code Llama (Meta): Open-source, specialized for code, and StarCoder: Open alternative for commercial use. Choice depends on your specific needs (cost, privacy, deployment options).
How do LLMs understand context?
LLMs use the self-attention mechanism in transformers to understand context. For each word/token, the model: Computes attention scores with all other tokens in the sequence, weighs the importance of each token relative to others, creates contextual representations that capture relationships, and uses multiple attention heads to capture different types of relationships simultaneously. This allows the model to understand long-range dependencies, disambiguate word meanings based on context, and maintain coherence across long passages.
What are the ethical concerns with LLMs?
Key ethical concerns include: Bias and fairness (reflecting societal biases in training data), misinformation (generating convincing but false content), privacy (memorizing and potentially leaking training data), job displacement (automating knowledge work), environmental impact (energy consumption for training and inference), copyright issues (training on copyrighted content), and misuse (generating harmful content, spam, or propaganda). Addressing these requires ongoing research, regulation, and responsible deployment practices.
How I Can Help You with LLM Projects
As an AI/ML engineer with extensive experience in Large Language Models and NLP, I’ve worked on various projects leveraging LLMs for real-world applications, from building intelligent chatbots to developing code generation tools and document analysis systems.
Whether you’re looking to integrate LLMs into your product, fine-tune models for specific domains, or optimize inference costs, I can help you navigate the complexities and build production-ready solutions.
LLM Integration & Development
Build and deploy LLM-powered applications with optimal performance and cost efficiency.
View AI Projects →Model Fine-tuning & Optimization
Customize pre-trained models for your specific domain and optimize for production deployment.
Get in Touch →Conclusion
Large Language Models represent one of the most transformative technologies of our time. From the foundational transformer architecture to advanced training techniques like RLHF, understanding how these models work is crucial for anyone building AI-powered applications.
As we’ve explored in this comprehensive guide, LLMs offer immense potential, from code generation to customer support, content creation to research assistance. However, they also come with challenges: hallucinations, biases, computational costs, and ethical concerns that require careful consideration.
The future of LLMs is exciting: multimodal capabilities, longer context windows, more efficient architectures, and smarter agents. But success in this space requires not just understanding the technology, but also mastering prompt engineering, deployment strategies, and cost optimization.
Whether you’re a developer building AI applications, a researcher pushing the boundaries of what’s possible, or a business leader evaluating AI opportunities, I hope this guide has given you the foundational knowledge to work effectively with Large Language Models.
Ready to build something with LLMs? Explore my AI projects or get in touch to discuss your next AI initiative.